Final presentations second AI for Health course

Friday, February 12, 2021, the second edition of the AI for Health course concluded with a meeting where all participants presented the results of their AI projects. The course was followed by about 25 RadboudUMC employees from various backgrounds, offering them a deep dive into the possibilities of AI in healthcare. The third edition of the AI for Health course is scheduled to start in September 2021, if you are interested you can send an e-mail to aiforhealth@radboudumc.nl.
The course is organized by the RadboudUMC in collaboration with the Jheronimus Academy of Data Science (JADS) in Den Bosch. During 14 Fridays the participants got an overview of the various AI applications in healthcare and all the aspects that need be taken into account to successfully implement AI in your work. At the end of the course the participants worked in project teams on an AI application of their choice for 4 days.
Arjen de Boer, Michael Ricking, Purva Kulkarni and Rob Tolboom worked on Classifying patient with inborn errors of metabolism using machine learning. Mass-spectrometry data is notoriously high dimensional, making it difficult to identify biomarkers for inborn errors. Using dimensionality reduction techniques the team identified several potential biomarkers for inborn errors. Further validation on future data will teach us how valuable these biomarkers are for predicting inborn errors.
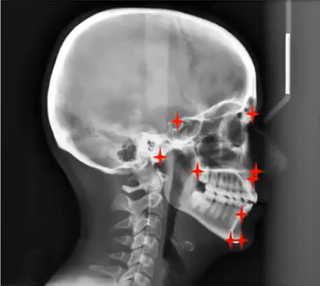
Frits Rangel, Charlotte Ijsbrandy, Stan Wijn, Ward de Witte and Stani Sparreboom-Kalaykova created an algorithm to Automatically detect orthodontic landmarks on lateral headplates. Such landmarks provide an orthodontist with important measurements before an intervention, but identifying them takes up valuable time from the orthodontist. Their results showed good performance on a subset of the landmarks, showing potential to fully automate this process.
Fiona Zegwaard, Gijs van de Veen and Dirk Geurts worked on a machine learning approach to Predict who might not benefit from mindfulness based cognitive therapy. This therapy helps to reduce depressive symptoms in many patients, but does not work for a subset of patients. Machine learning could potentially identify patients for whom the treatment is not suited, but the current data set did not provide insights to improve predictions of treatment outcome. To improve the data set potential extra data features have been suggested that could help prediction of treatment outcome.
Maarten Arends, Roberto Garcia van der Westen, Chris Peters, Ingrid van Weerdenburg and Berti Moonen made an algorithm to Predict the length of stay for ICU patients. The planning of operations depends strongly on the predicted length of stay for patients after operation. Currently the length of stay is predicted purely on the type of operation that a patient undergoes. The team tried to improve these predictions by adding more patient data and using a machine learning approach. A slight improvement in predictions was achieved, but further work is necessary to make it a valuable tool on the ICU.
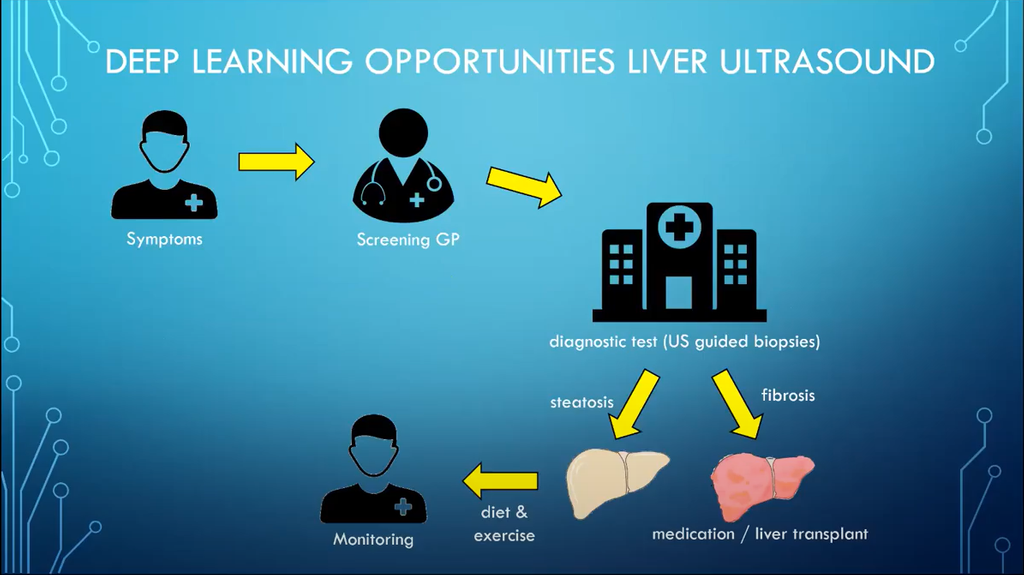
Gert Weijers, Jonne Doorduin, Anton Meijer and Jan-Willem Wasmann worked on the Prediction of steatosis and fibrosis from liver ultrasound using deep learning. Liver biopsies are currently necessary in selected patients to identify liver fibrosis, leading to risk of bleeding associated complications. The team created a deep learning algorithm to recognize the steatosis and fibrosis from ultrasound images. The algorithm learned to reliably detect steatosis, but fibrosis was more challenging to identify. More data from fibrosis patients will hopefully improve this in the future.
← Back to overview